Ch-16 查询优化
1. 优化基础
1.1 优化目标
查询优化 (Query Optimization) 的目标是在多个等价执行方案中选择估计代价最低的方案。SQL 会先被解析并翻译成关系代数表达式,优化器再进行逻辑改写、物理算法选择和代价比较,最后把执行计划交给执行引擎。
优化可以分为两层:逻辑优化 改写表达式,如选择下推、投影下推、连接重排;物理优化 选择访问路径和算子算法,如索引扫描、哈希连接、归并连接。同一逻辑表达式可以对应许多物理计划,优化器比较的是整棵计划树的代价,而不是某个算子的局部代价。
1.2 代价来源
基于代价的优化 (Cost-Based Optimization) 通常做三件事:先用等价规则生成逻辑等价表达式,再给表达式标注不同物理算法得到候选计划,最后根据估计代价选最便宜者。
计划代价主要依赖三类信息:
| 信息 | 用途 |
|---|---|
| 基表统计 | 元组数、块数、属性不同值数 |
| 中间统计 | 估计子表达式输出大小 |
| 算法公式 | 估计 I/O、CPU、内存代价 |
最关键也最容易出错的是 基数估计 (Cardinality Estimation)。一个选择或连接的输出规模估错,后续连接顺序、访问路径和算法选择都会被带偏。
explain select *
from instructor
where dept_name = 'Music';许多数据库支持 explain 查看执行计划。PostgreSQL 的 explain analyse 会真实执行查询并显示运行统计。
某些系统用 f..l 表示代价区间。
其中 \(f\) 是返回第一条结果的代价。
其中 \(l\) 是返回全部结果的代价。
Note
优化器选择的是估计最优计划。统计信息过旧、属性相关性强、数据倾斜明显时,估计代价和真实代价可能相差很大。
2. 等价变换
2.1 基本规则
两个关系代数表达式如果在任意合法数据库实例上产生相同结果,就称为 等价 (Equivalent)。SQL 常采用多重集语义,因此还要保持重复元组次数。
常见等价规则如下:
| 规则 | 公式 | 作用 |
|---|---|---|
| 选择分解 | \(\sigma_{\theta_1\land\theta_2}(E)=\sigma_{\theta_1}(\sigma_{\theta_2}(E))\) | 拆开复杂条件 |
| 选择交换 | \(\sigma_{\theta_1}(\sigma_{\theta_2}(E))=\sigma_{\theta_2}(\sigma_{\theta_1}(E))\) | 先做选择率低的条件 |
| 投影合并 | \(\Pi_{L_1}(\Pi_{L_2}(E))=\Pi_{L_1}(E)\),\(L_1\subseteq L_2\) | 删除无用投影 |
| 连接交换 | \(E_1\bowtie E_2=E_2\bowtie E_1\) | 调整左右输入 |
| 连接结合 | \((E_1\bowtie E_2)\bowtie E_3=E_1\bowtie(E_2\bowtie E_3)\) | 枚举连接顺序 |
选择可以和笛卡尔积合并,把“先生成大结果再过滤”改成条件连接:\(\sigma_{\theta}(E_1\times E_2)=E_1\bowtie_{\theta}E_2\)。
连接后的选择条件也可以合并进连接谓词,让物理算法更早利用过滤条件:\(\sigma_{\theta_1}(E_1\bowtie_{\theta_2}E_2)=E_1\bowtie_{\theta_1\land\theta_2}E_2\)。
2.2 下推规则
选择下推 (Selection Pushdown) 把过滤条件移动到靠近基表的位置。
若 \(\theta_0\) 只涉及 \(E_1\) 的属性,选择可以先作用在左侧输入上,形式为 \(\sigma_{\theta_0}(E_1\bowtie_{\theta}E_2)=(\sigma_{\theta_0}(E_1))\bowtie_{\theta}E_2\)。
若 \(\theta_1\) 只涉及 \(E_1\),\(\theta_2\) 只涉及 \(E_2\),则:
\[ \sigma_{\theta_1\land\theta_2}(E_1\bowtie_{\theta}E_2)=(\sigma_{\theta_1}(E_1))\bowtie_{\theta}(\sigma_{\theta_2}(E_2)) \]选择会减少元组数,越早执行,后续连接、排序、哈希和物化的数据越少。
投影下推 (Projection Pushdown) 提前删除后续不需要的属性。
设最终输出需要的属性来自两侧,记为 \(L_1\cup L_2\)。
若连接条件 \(\theta\) 还需要 \(E_1\) 中属性 \(L_3\) 和 \(E_2\) 中属性 \(L_4\),则:
\[ \Pi_{L_1\cup L_2}(E_1\bowtie_{\theta}E_2)=\Pi_{L_1\cup L_2}(\Pi_{L_1\cup L_3}(E_1)\bowtie_{\theta}\Pi_{L_2\cup L_4}(E_2)) \]投影下推不减少元组数,但会减小元组宽度,降低 I/O、内存、排序和哈希代价。
2.3 集合聚集
并集和交集满足交换律与结合律,差集不满足交换律。选择可以分配到集合差中:\(\sigma_{\theta}(E_1-E_2)=\sigma_{\theta}(E_1)-\sigma_{\theta}(E_2)\)。
如果条件只过滤左侧,还可以只把选择作用到左侧,交集也有类似规则,但并集不适用这个简化:\(\sigma_{\theta}(E_1-E_2)=\sigma_{\theta}(E_1)-E_2\)。
投影可以分配到并集:\(\Pi_L(E_1\cup E_2)=\Pi_L(E_1)\cup\Pi_L(E_2)\)。
聚集也能与选择交换,但选择条件只能引用分组属性 \(G\)。
设 \(G\gamma_A(E)\) 表示按 \(G\) 分组并计算聚集 \(A\)。
提前过滤分组属性只会删除整组,不会改变组内聚集值,等价式为 \(\sigma_{\theta}(G\gamma_A(E))=G\gamma_A(\sigma_{\theta}(E))\)。
2.4 外连接
外连接要保留不匹配元组并补 null,因此不能随意套用内连接规则。全外连接满足交换律:\(E_1\mathbin{\text{⟗}}E_2=E_2\mathbin{\text{⟗}}E_1\)。
左外连接和右外连接可以交换方向:\(E_1\mathbin{\text{⟕}}E_2=E_2\mathbin{\text{⟖}}E_1\)。
外连接一般不满足结合律,改变连接顺序可能改变哪些元组被补 null:\((r\mathbin{\text{⟕}}s)\mathbin{\text{⟕}}t\ne r\mathbin{\text{⟕}}(s\mathbin{\text{⟕}}t)\)。
若 \(\theta_1\) 只涉及左侧 \(E_1\),则选择可以下推到左侧输入,形式为 \(\sigma_{\theta_1}(E_1\mathbin{\text{⟕}}_{\theta}E_2)=(\sigma_{\theta_1}(E_1))\mathbin{\text{⟕}}_{\theta}E_2\)。
若 \(\theta_1\) 对右侧属性是 NULL 拒绝 (Null Rejecting) 的,即右侧属性为 null 时条件结果为 false 或 unknown,则补出的 null 元组最终都会被过滤。
此时左外连接可替换为内连接,形式为 \(\sigma_{\theta_1}(E_1\mathbin{\text{⟕}}_{\theta}E_2)=\sigma_{\theta_1}(E_1\bowtie_{\theta}E_2)\)。
2.5 生成计划
直接反复对所有子表达式套用等价规则会非常耗时,也会生成许多重复表达式。优化器通常共享公共子表达式:当 \(E_1\) 由 \(E_2\) 顶层改写得到时,底层子树可以共用指针。重复生成的子表达式需要检测并合并。
Volcano 风格优化器使用 备忘录 (Memoization) 保存等价表达式类和已知最优计划;第一次优化某个子表达式后缓存结果,之后复用。实际系统还会做代价剪枝,避免生成明显不可能最优的计划。
3. 基数估计
3.1 基本统计
优化器依赖系统目录中的统计量:
| 统计量 | 含义 |
|---|---|
| \(n_r\) | 关系 \(r\) 的元组数 |
| \(b_r\) | 关系 \(r\) 的块数 |
| \(l_r\) | 关系 \(r\) 的元组大小 |
| \(f_r\) | 关系 \(r\) 的阻塞因子 |
\(V(A,r)\) 表示属性 \(A\) 在 \(r\) 中的不同值数量,也就是 \(\Pi_A(r)\) 的大小。
若 \(r\) 的元组连续存放,则块数可由元组数和阻塞因子估计:\(b_r=\lceil n_r/f_r\rceil\)。
直方图 (Histogram) 比单个不同值数量更精细。等宽直方图按取值范围等宽分桶,等深直方图让每个桶的元组数接近;当数据分布不均匀时,直方图能改进选择率估计。
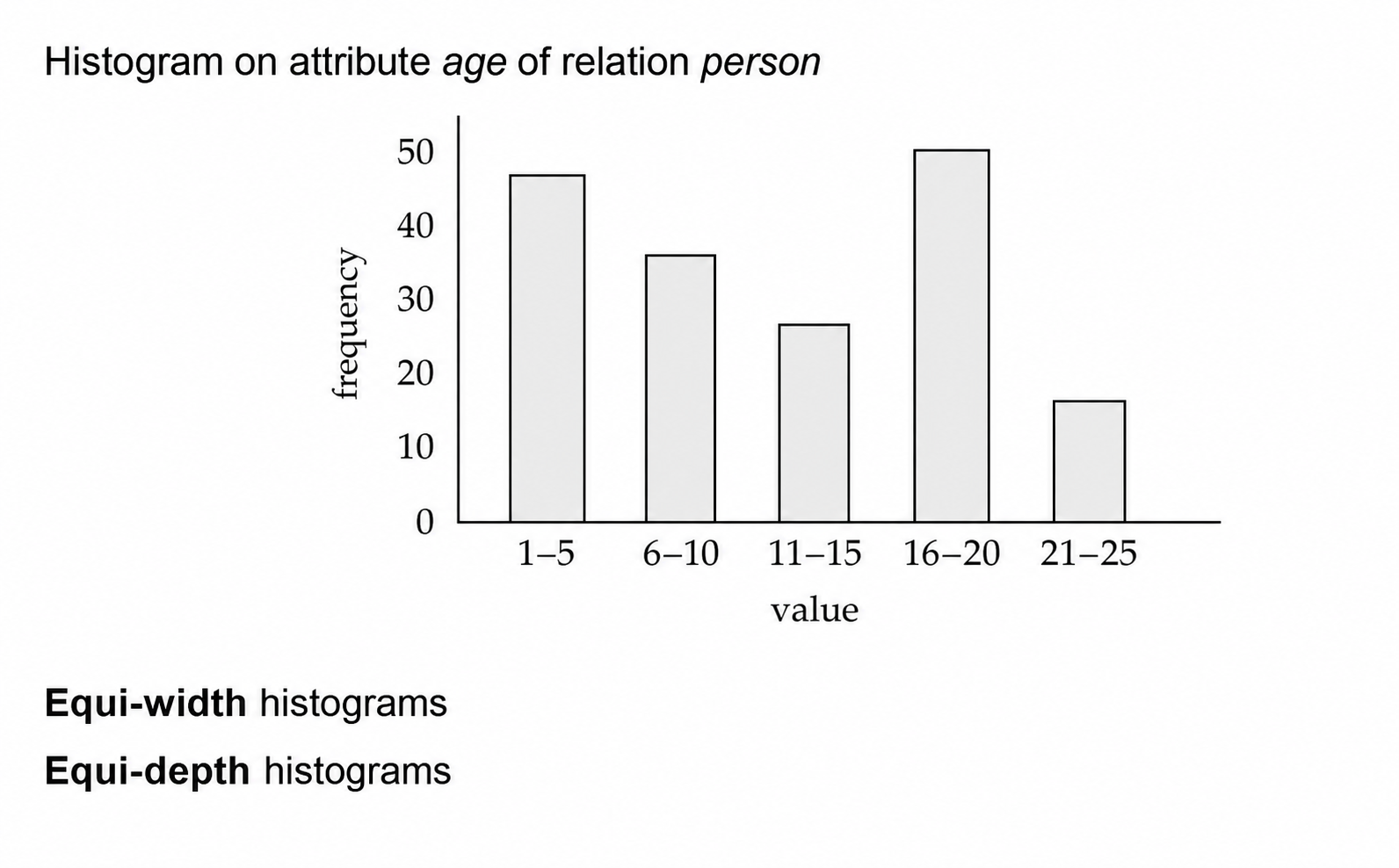
3.2 选择大小
等值选择 \(\sigma_{A=v}(r)\) 在均匀分布假设下,平均每个值对应的元组数为 \(n_r/V(A,r)\)。
因此等值选择结果大小约为 \(\text{size}(\sigma_{A=v}(r))\approx n_r/V(A,r)\)。
若 \(A\) 是键,每个取值最多对应一个元组,因此结果大小估计为 \(1\)。
范围选择 \(\sigma_{A\le v}(r)\) 可利用目录中的 \(\min(A,r)\) 和 \(\max(A,r)\)。设满足条件的元组数为 \(c\):
\[ c=\begin{cases}0, & v<\min(A,r)\\n_r, & v\ge \max(A,r)\\n_r\cdot\dfrac{v-\min(A,r)}{\max(A,r)-\min(A,r)}, & \min(A,r)\le v<\max(A,r)\end{cases} \]这个估计默认取值均匀分布;有直方图时按桶估计再相加;没有统计信息时,常把范围选择估为 \(n_r/2\)。
3.3 复杂选择
选择率 (Selectivity) 是元组满足条件的概率。
若条件 \(\theta_i\) 有 \(s_i\) 个满足元组,则选择率为 \(s_i/n_r\)。
下面用 \(p_i\) 表示条件 \(\theta_i\) 的选择率。
若假设条件独立,合取条件要求元组同时满足所有条件,结果大小估计为 \(n_r\prod_{i=1}^{n}p_i\)。
析取条件可以先计算“不满足任何条件”的概率,再取补集:\(\text{size}(\sigma_{\theta_1\lor\cdots\lor\theta_n}(r))\approx n_r(1-\prod_{i=1}^{n}(1-p_i))\)。
否定条件直接从总元组数中减去原条件结果:\(\text{size}(\sigma_{\neg\theta}(r))=n_r-\text{size}(\sigma_{\theta}(r))\)。
Note
独立性假设很常用,但并不总可靠。例如 dept_name 和 building 往往相关,直接相乘可能明显低估或高估结果大小。
3.4 连接大小
笛卡尔积的每个元组都与另一个关系的所有元组配对,因此元组数为 \(n_rn_s\)。
若两个关系没有公共属性,自然连接退化为笛卡尔积,即 \(R\cap S=\emptyset\)。
若公共属性 \(R\cap S\) 是 \(R\) 的键,一个 \(s\) 元组至多匹配一个 \(r\) 元组,因此 \(\text{size}(r\bowtie s)\le n_s\)。
若公共属性 \(R\cap S\) 是 \(s\) 中引用 \(r\) 的外键并满足参照完整性,每个 \(s\) 元组都能匹配到一个 \(r\) 元组,因此 \(\text{size}(r\bowtie s)=n_s\)。
若公共属性只有 \(A\),且没有键或外键信息,把 \(s\) 看作探测 \(r\) 时,可按 \(r\) 中不同连接值数平均分摊,估计为 \(n_rn_s/V(A,r)\)。
反过来,把 \(r\) 看作探测 \(s\) 时,估计为 \(n_rn_s/V(A,s)\)。
通常取两种估计的较小者:
\[ \text{size}(r\bowtie s)\approx\frac{n_rn_s}{\max(V(A,r),V(A,s))} \]例如 student 与 takes 在 ID 上连接,相关统计量如下:
| 统计量 | 数值 |
|---|---|
| \(n_{\text{student}}\) | \(5000\) |
| \(n_{\text{takes}}\) | \(10000\) |
| \(V(\text{ID},\text{student})\) | \(5000\) |
| \(V(\text{ID},\text{takes})\) | \(2500\) |
不使用外键信息时,按 takes 中不同 ID 数估计,结果大小为 \(5000\times10000/2500=20000\)。
按 student 中不同 ID 数估计,结果大小为 \(5000\times10000/5000=10000\)。
因此取较小估计,连接结果大小为 \(10000\)。
若知道 takes.ID 是引用 student.ID 的外键,也可直接得到连接结果大小为 \(\text{size}(\text{student}\bowtie\text{takes})=n_{\text{takes}}=10000\)。
3.5 其它大小
投影结果只保留属性 \(A\) 的不同取值,大小可估为 \(\text{size}(\Pi_A(r))=V(A,r)\)。
按 \(A\) 分组聚集时,每个不同的 \(A\) 值形成一组,结果大小也可估为 \(V(A,r)\)。
同一关系上的选择并、交、差,可先改写成选择条件再估计。例如两个选择结果求并时,可合并为析取选择,\(\sigma_{\theta_1}(r)\cup\sigma_{\theta_2}(r)=\sigma_{\theta_1\lor\theta_2}(r)\)。
不同关系上的集合操作常用上界估计:
| 操作 | 估计 |
|---|---|
| 并 | \(\text{size}(r\cup s)\approx\text{size}(r)+\text{size}(s)\) |
| 交 | \(\text{size}(r\cap s)\approx\min(\text{size}(r),\text{size}(s))\) |
| 差 | \(\text{size}(r-s)\approx\text{size}(r)\) |
左外连接要保留左侧未匹配元组,粗略估计为 \(\text{size}(r\mathbin{\text{⟕}}s)\approx\text{size}(r\bowtie s)+\text{size}(r)\)。
全外连接还要保留右侧未匹配元组,粗略估计为 \(\text{size}(r\mathbin{\text{⟗}}s)\approx\text{size}(r\bowtie s)+\text{size}(r)+\text{size}(s)\)。
3.6 不同值数
中间结果的不同值数会继续影响后续估计。对于选择结果 \(\sigma_{\theta}(r)\):
| 情况 | 估计 |
|---|---|
| \(\theta\) 强制 \(A\) 等于某值 | \(V(A,\sigma_{\theta}(r))=1\) |
| \(\theta\) 强制 \(A\) 属于 \(k\) 个值 | \(V(A,\sigma_{\theta}(r))=k\) |
| \(\theta\) 形如 \(A\ \text{op}\ v\) | \(V(A,\sigma_{\theta}(r))\approx V(A,r)\cdot p\) |
| 其它情况 | \(\min(V(A,r),n_{\sigma_{\theta}(r)})\) |
对于连接结果,若属性集 \(A\) 全部来自 \(r\),不同值数不会超过原关系中的不同值数,也不会超过连接结果大小,估计为 \(V(A,r\bowtie s)=\min(V(A,r),n_{r\bowtie s})\)。
若 \(A\) 同时包含来自 \(r\) 的属性 \(A_1\) 和来自 \(s\) 的属性 \(A_2\),可分别从两侧属性组合给出上界:
\[ V(A,r\bowtie s)=\min(V(A_1,r)V(A_2-A_1,s),V(A_1-A_2,r)V(A_2,s),n_{r\bowtie s}) \]投影后的不同值数量与原关系对应属性相同。
分组属性 \(G\) 的不同值数量决定聚集结果组数。
对 min(A)、max(A),每组只产生一个极值,极值数量不会超过原属性值数或组数,估计为 \(\min(V(A,r),V(G,r))\)。
其它聚集值通常缺少更强统计信息,常粗略估为 \(V(G,r)\)。
4. 计划搜索
4.1 搜索空间
优化器不能独立选择每个算子的最便宜算法。归并连接可能比哈希连接贵,但它产生的有序输出可被后续 order by、分组或归并连接利用;嵌套循环连接也可能带来流水线机会。
对 \(r_1\bowtie r_2\bowtie\cdots\bowtie r_n\),不同连接顺序数量随关系数快速增长,数量为 \(\frac{(2(n-1))!}{(n-1)!}\)。
当 \(n=3\) 时有 \(12\) 种连接顺序。
当 \(n=5\) 时有 \(1680\) 种连接顺序。
当 \(n=10\) 时连接顺序超过 \(1760\) 亿种,必须用动态规划或启发式减少搜索。
4.2 动态规划
动态规划 (Dynamic Programming) 为每个关系子集保存最优计划,记为 \(\text{Best}[S]\)。
对集合 \(S\),枚举左右两侧划分,形式为 \(S_1\bowtie(S-S_1)\)。
枚举某个划分后,复用两侧子问题的最优计划,再尝试不同连接算法。
\begin{algorithm}
\caption{FindBestPlan(S)}
\begin{algorithmic}
\IF{\text{Best}[S]\text{ exists}} \RETURN \text{Best}[S] \ENDIF
\IF{|S|=1} \RETURN \text{best access path for }S \ENDIF
\FOR{\text{each nonempty proper subset }S_1\subset S}
\STATE P_1\gets \text{FindBestPlan}(S_1)
\STATE P_2\gets \text{FindBestPlan}(S-S_1)
\STATE \text{try join algorithms and keep the cheapest plan}
\ENDFOR
\RETURN \text{Best}[S]
\end{algorithmic}
\end{algorithm}单关系基本情况要考虑选择条件和可用索引;连接算法也要考虑方向,例如索引嵌套循环的内外表、哈希连接的构建输入。
若允许 bushy tree,动态规划时间复杂度约为 \(O(3^n)\)。
此时需要保存所有关系子集的最优计划,空间复杂度为 \(O(2^n)\)。
4.3 左深树
左深连接树 (Left-Deep Join Tree) 要求每次连接的右侧输入都是一个基关系,而不是中间连接结果。
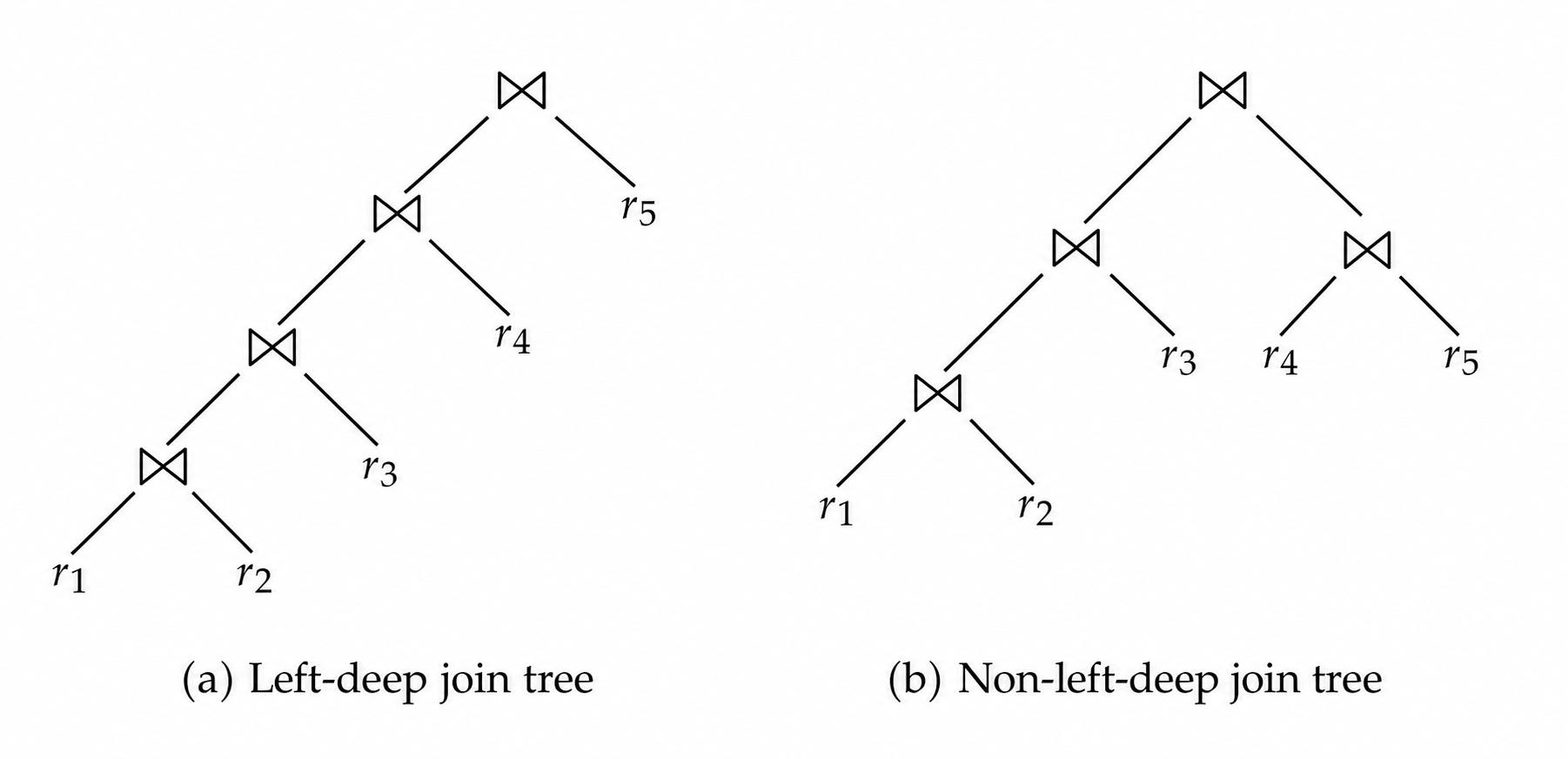
只考虑左深树时,对集合 \(S\) 只枚举右侧基关系 \(r\),即 \((S-\{r\})\bowtie r\)。
这样时间复杂度降为 \(O(n2^n)\)。
由于仍需保存关系子集的最优计划,空间复杂度仍为 \(O(2^n)\)。
左深树适合流水线执行,也便于使用索引嵌套循环连接。
4.4 有趣顺序
有趣排序 (Interesting Sort Order) 是当前算子未必需要、但后续算子可能利用的中间结果顺序。
例如三个关系都在属性 \(A\) 上连接,典型形态为 \((r_1\bowtie r_2)\bowtie r_3\)。
用归并连接计算 \(r_1\bowtie r_2\) 可能比哈希连接贵,但会生成按 \(A\) 排序的结果,使后续归并连接更便宜。
因此优化器不能只为每个关系子集保存一个最低代价计划,还要为不同有趣排序保存候选计划。通常有趣排序数量不多,不会显著改变动态规划复杂度。
4.5 优化器结构
启发式优化 (Heuristic Optimization) 用规则快速减少搜索空间:尽早执行选择、尽早执行投影、优先执行结果小的选择和连接、优先考虑左深树。实际优化器常先做嵌套查询、聚集和选择投影下推,再对每个查询块做代价型连接顺序优化。
有些系统只对查询块做优化,有些系统会把变换应用到整条 SQL。由于优化本身有成本,系统会设置优化预算:若当前计划已经足够便宜,可能提前停止搜索。计划缓存也很常见,相同查询再次提交时可复用已有计划,即使常量值不同也可能共享参数化计划。
5. 高级优化
5.1 子查询优化
SQL 概念上把嵌套子查询当成带参数的函数。若子查询引用外层变量,这些变量称为 相关变量 (Correlation Variable)。直接对外层每个元组执行一次子查询称为 相关执行 (Correlated Evaluation),通常代价很高。
select name
from instructor
where exists (
select *
from teaches
where instructor.ID = teaches.ID
and teaches.year = 2022
);优化器会尽量把相关子查询改写为连接或半连接。上例可表示为:
\[ \Pi_{\text{name}}(\text{instructor}\ltimes_{\text{instructor.ID}=\text{teaches.ID}\land \text{teaches.year}=2022}\text{teaches}) \]半连接 (Semijoin) 只保留左侧有匹配的元组,不拼接右侧属性。
左侧某个元组出现多次时,只要右侧存在匹配,这些出现次数仍会保留;例如左侧出现次数为 \(n\)。
一般形式中,若 \(P_{21}\) 不涉及相关变量,\(P_{22}\) 涉及相关变量:
select A
from r1, r2, ..., rn
where P1 and exists (
select *
from s1, s2, ..., sm
where P21 and P22
);可改写为:
\[ \Pi_A(\sigma_{P_1}(r_1\times r_2\times\cdots\times r_n)\ltimes_{P_{22}}\sigma_{P_{21}}(s_1\times s_2\times\cdots\times s_m)) \]这种把相关子查询替换为连接或半连接的过程称为 去相关 (Decorrelation)。若子查询包含聚集或标量结果,去相关更复杂;有些标量聚集可先 group by 再半连接,有些仍需相关执行。
5.2 物化维护
物化视图 (Materialized View) 把视图结果预先计算并存储。它能减少重复计算,但底层关系更新后必须维护。维护可通过重新计算、触发器、手写维护代码或周期性刷新完成;更高效的方法是 增量视图维护 (Incremental View Maintenance)。
设物化视图是两个关系的连接,记为 \(v=r\bowtie s\)。
插入到 \(r\) 的元组集合记为 \(i_r\)。
删除自 \(r\) 的元组集合记为 \(d_r\)。
插入时,新的关系内容可表示为 \(r_{\text{new}}=r_{\text{old}}\cup i_r\)。
因此只需把新增元组与另一侧关系连接后加入视图,得到 \(v_{\text{new}}=v_{\text{old}}\cup(i_r\bowtie s)\)。
删除时只需移除被删除元组原本贡献的连接结果,得到 \(v_{\text{new}}=v_{\text{old}}-(d_r\bowtie s)\)。
选择视图维护也直接,设视图为 \(v=\sigma_{\theta}(r)\)。
插入时,只把满足条件的新元组加入视图,得到 \(v_{\text{new}}=v_{\text{old}}\cup\sigma_{\theta}(i_r)\)。
删除时,只从视图中移除满足条件的旧元组,得到 \(v_{\text{new}}=v_{\text{old}}-\sigma_{\theta}(d_r)\)。
投影更麻烦,因为多个原始元组可能投影成同一元组,通常要维护引用计数;计数降为 \(0\) 时才删除投影结果。
聚集维护按函数区分:
| 聚集 | 插入 | 删除 |
|---|---|---|
count | 计数加一 | 计数减一 |
sum | 加上新值 | 减去旧值 |
avg | 维护 sum 和 count | 维护 sum 和 count |
min、max | 比较新值 | 删除当前极值可能重扫分组 |
复杂表达式的维护可自底向上进行:先求最小子表达式的差分,再把差分向上组合。
例如连接表达式为 \(E_1\bowtie E_2\)。
若 \(E_1\) 的插入差分为 \(D_1\),则该连接的插入差分为 \(D_1\bowtie E_2\)。
5.3 视图改写
优化器可以使用已有物化视图改写查询。若已有物化视图覆盖了前两个关系的连接,记为 \(v=r\bowtie s\)。
此时查询可以用物化视图替代局部连接,例如 \(r\bowtie s\bowtie t\) 可改写为 \(v\bowtie t\)。
但是否使用物化视图仍取决于代价:若 \(v\) 没有合适索引,而原始关系上有索引,展开 \(v\) 的定义可能更便宜。
例如查询需要在物化视图上选择,表达式为 \(\sigma_{A=10}(v)\)。
若 \(v=r\bowtie s\)、\(r.A\) 有索引且 \(s\) 的连接属性有索引,则先选择再连接可能比扫描 \(v\) 更好。
这个先选择再连接的计划可写为 \(\sigma_{A=10}(r)\bowtie s\)。
物化视图选择 (Materialized View Selection) 要决定哪些视图值得物化。它和索引选择类似,目标是在工作负载、空间限制、查询时间和更新维护成本之间取舍。
5.4 其它优化
查询优化还包括:
| 主题 | 核心问题 |
|---|---|
| Top-K 查询 | 只取前 \(K\) 个结果时避免完整排序 |
| 更新优化 | 防止更新中重复处理同一元组 |
| 连接消除 | 删除不影响结果的冗余连接 |
| 多查询优化 | 多个查询共享公共子表达式 |
| 参数化优化 | 参数值不同可能对应不同最优计划 |
| 自适应优化 | 运行时发现估计偏差后调整计划 |
Top-K 查询只需要保留排序后的前若干个结果,例如 order by r.A limit 10。
这类查询可以用以 \(r\) 为外层的索引嵌套循环连接。
另一种做法是估计结果中最大的 r.A 上界,记为 \(H\)。
随后加入 r.A <= H 缩小输入;若结果不足 \(10\) 条,再放宽 \(H\)。
Halloween Problem 出现在更新优化中:
update R
set A = 5 * A
where A > 10;若系统用 \(A\) 上索引查找 A > 10,并在扫描时立即更新 \(A\),同一元组可能因新值仍满足条件而被再次找到。解决方法是先收集待更新元组再统一更新;或仅当更新影响 where 条件中的属性时延迟更新。
连接消除用于删除冗余连接。例如:
select r.A, r.B
from r, s
where r.B = s.B;若 r.B 是非空外键并引用 s.B,且查询不输出 s 的属性,也没有 s 上的过滤条件,则连接 s 不改变结果,可以删除。多查询优化则会寻找多个查询中的公共子表达式,例如两个查询都能共享 \(r\bowtie s\);共享不一定总便宜,因此仍需代价判断。自适应优化会在运行时发现估计行数偏差过大时,重新选择或调整计划,但要避免频繁重启带来的额外成本。